
C-Eval是由上海交通大学、清华大学与爱丁堡大学研究团队于2023年5月联合推出的中文大语言模型专属评估套件,聚焦模型的中文理解与应用能力评测。套件包含13948道标准化多项选择题,覆盖52个学科领域、划分四个难度等级,通过零样本(zero-shot)和少样本(few-shot)测试模式,可精准评估模型在未见过的任务中的适应性与泛化能力,是中文大语言模型性能评测的核心基准工具。

C-Eval核心功能:
1、全领域多学科覆盖:
涵盖STEM、社会科学、人文科学等52个学科领域的评测题目,全方位考察模型的跨领域知识储备与中文理解能力。
2、精细化难度分级:
设置从基础到高级的四个难度级别,可细致评估模型在不同难度梯度下的逻辑推理、知识应用与泛化能力。
3、标准化量化评估:
基于13948道标准化多项选择题搭建评测体系,搭配统一评分系统输出量化性能指标,支持不同大语言模型的横向对比与性能溯源。
4、零样本/少样本双模式测试:
适配零样本、少样本两种主流评测模式,精准衡量模型在无标注或少量标注任务中的自适应能力,贴合实际应用场景需求。
C-Eval多领域应用场景:
1、大模型研发与性能优化:
为模型开发者提供标准化的中文能力评测基准,全面衡量模型的知识水平、推理能力与中文适配性,为模型迭代、调优提供精准的数据支撑。
2、学术研究与模型对比:
作为NLP领域的标准化测试平台,助力研究人员客观分析、横向对比不同中文大语言模型在各学科的表现,为学术研究、算法改进提供核心参考,推动中文大模型技术发展。
3、教育领域智能化开发:
依托多学科、多难度的评测题库与模型能力评估体系,助力智能辅导系统、教育评估工具的研发,可实现智能化练习题生成、答题自动评分等功能,提升教育领域智能化水平。
4、行业大模型落地优化:
针对金融、医疗、智能客服等垂直领域,精准评估行业大模型的领域知识储备与实际应用能力,为行业智能化解决方案的优化、落地提供评测依据,提升场景适配效果。
5、社区技术交流与赛事评测:
作为开放的中文大模型评估平台,促进开发者社区的技术交流与合作,同时为各类中文大模型竞赛、技术评测提供公平、统一的基准测试工具,推动行业生态共建。
EdgeClaw AI智能体框架使用入口,面壁智能联合清华、OpenBMB等机构推出的开源AI智能体框架
OpenMAIC官网使用入口,清华THU MAIC研发的开源AI互动教育平台
OpenMAIC官网使用入口,清华团队开源的多智能体AI课堂平台
DreamID-Omni虚拟数字人模型,清华 × 字节跳动统一可控以人为中心音视频生成框架
Ctrl-World模型使用入口,厘米级轨迹精度、0.986的策略评估一致性及0.93的深度准确性
标签: AI模型评测, 上海交通大学, 基础模型评估, 清华大学, 爱丁堡大学
上面是“C-Eval官网:多学科多层次中文大语言模型权威评估套件”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_28209.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 Presentations.AI:一款基于生成式人工智能的在线演示文稿制作平台
Presentations.AI:一款基于生成式人工智能的在线演示文稿制作平台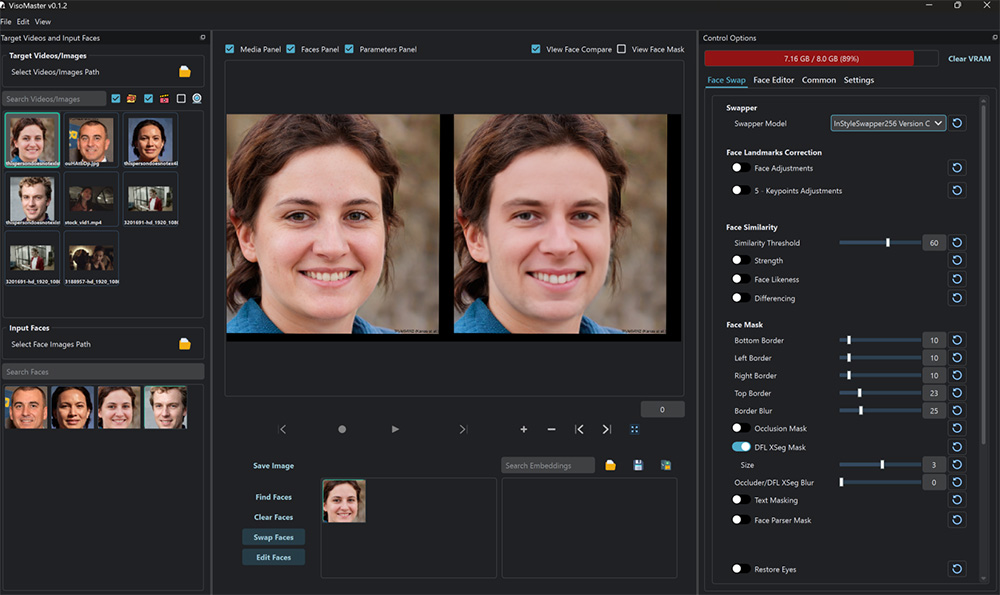 VisoMaster:一款功能强大且易于使用的AI换脸和编辑软件
VisoMaster:一款功能强大且易于使用的AI换脸和编辑软件 多多进宝:拼多多官方推出的一个推广平台,类似于淘宝客
多多进宝:拼多多官方推出的一个推广平台,类似于淘宝客 一款由阿里通义万相视频生成AI大模型——WanX 2.1
一款由阿里通义万相视频生成AI大模型——WanX 2.1 SaySo AI语音输入助手,Mac与Windows双平台的智能语音输入助手
SaySo AI语音输入助手,Mac与Windows双平台的智能语音输入助手 面试通AI:一款AI面试笔试助手,助您通过笔试面试
面试通AI:一款AI面试笔试助手,助您通过笔试面试 帝国cms首页如何调用已注册会员人数和最新会员
帝国cms首页如何调用已注册会员人数和最新会员 易次元官网入口,一个面向喜欢二次元文化、互动小说和漫画的用户
易次元官网入口,一个面向喜欢二次元文化、互动小说和漫画的用户