
LingBot-VA是蚂蚁灵波科技开源的全球首个面向通用机器人控制的因果视频-动作世界模型,核心将视频世界建模与策略学习统一为自回归框架,让机器人实现未来状态预测+精确闭环控制双能力。模型具备极致的数据效率,仅需30-50次真实演示即可习得新技能,在长程任务执行、数据高效后训练、跨场景泛化能力上,显著优于业内主流基准模型,为通用机器人的智能控制提供核心技术支撑。
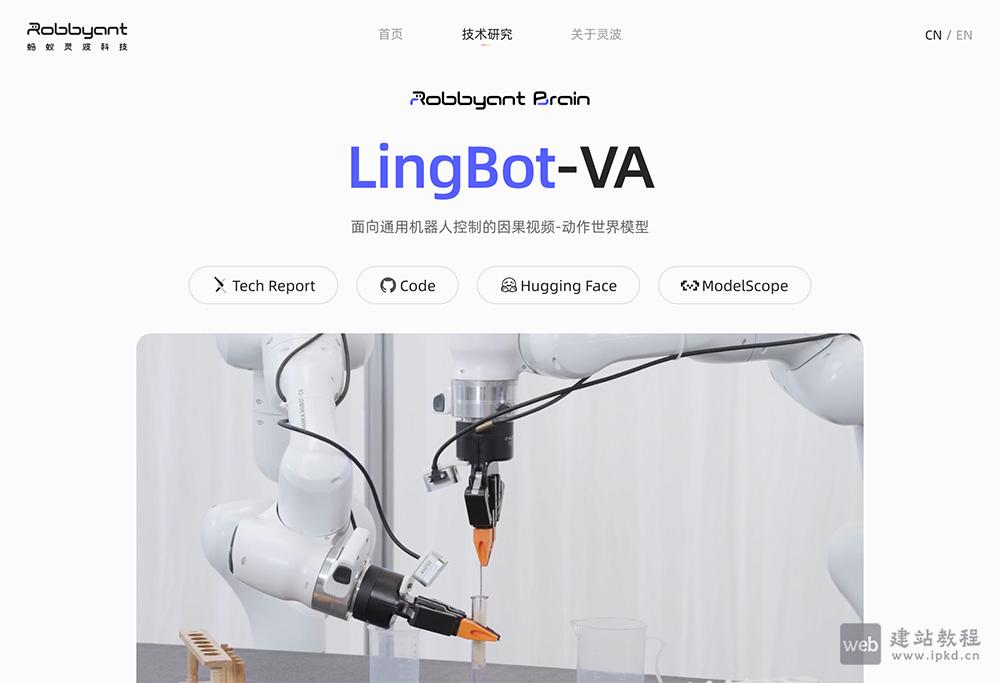
LingBot-VA主要功能:
1、视频-动作建模一体化:
将视觉动态预测与动作执行深度整合至单一框架,实现机器人“边想象未来状态、边执行精准动作”的闭环控制,让决策与执行高度协同。
2、长程复杂任务执行:
具备强大的长期记忆与多步骤规划能力,可高效完成准备早餐、拆包裹等多环节复合任务,不会因循环状态产生决策偏差。
3、超高效率后训练:
仅需30-50次真实演示即可快速学习新技能,技能习得成功率相较π₀.₅等基准模型提升约20%,大幅降低机器人技能训练的成本与周期。
4、全场景跨域泛化:
适配多类型机器人操作场景,支持亚毫米级精细操作(插入试管、拾取螺丝)、柔性物体处理(折叠衣物)、铰接物体控制(打开抽屉),适配不同物理场景的操作需求。
LingBot-VA技术原理:
1、自回归扩散架构:
采用自回归扩散核心框架,将视觉动态预测与动作推理融合为单一交错序列,让机器人可同步完成未来状态推理与精确闭环控制,实现视频生成与动作决策的深度耦合。
2、三阶段闭环处理框架:
分阶实现“预测-解码-锚定”全流程:① 自回归视频生成模块,根据当前视觉观测+语言指令,精准预测未来场景帧;② 逆向动力学模型(IDM),从预测视频中解码出具体可执行的动作指令;③ 动作执行后,以真实视觉观测替换视频KV-cache,将模型决策锚定实际结果,形成闭环控制并持续优化。
3、逆向动力学模型(IDM):
作为连接“状态想象”与“动作执行”的核心桥梁,可从预测视频中精准解码动作参数,在不同环境、不同机器人本体间具备优异的泛化能力,保障动作执行的通用性。
4、大规模真实数据预训练:
基于大规模机器人视频-动作数据集完成预训练,深度学习物理世界的视觉动态特性与动作关联逻辑,为机器人理解物理世界演变、实现精准操作奠定坚实基础。
LingBot-VA应用场景:
1、家庭服务长程任务:
落地家庭服务机器人场景,独立完成准备早餐、拆包裹、整理物品等需要多步骤规划、长期记忆的复合家庭任务,提升家庭机器人的智能服务能力。
2、高精度工业操作:
适配精密制造、实验室等工业场景,完成插入试管、拾取螺丝、微零件装配等亚毫米级高精度控制操作,提升工业自动化的精细度与效率。
3、柔性物体处理场景:
应用于物流、家政等领域,处理折叠衣物、整理软质包装等可变形柔性物体,精准理解物体材质特性,自适应动态形变过程,实现稳定操作。
4、铰接物体交互场景:
适配仓储、工业机器人场景,完成打开抽屉、操控阀门、调节机械结构等铰接物体操作,精准解析机械约束条件与运动学关系,保障操作准确性。
5、少样本快速适配场景:
针对新技能训练数据有限的场景(如定制化工业操作、小众服务任务),仅需30-50次真实演示即可让机器人习得新技能,实现低成本、快速的技能适配。
闲鱼智能监控机器人,能实时/定时监控闲鱼商品,自动过滤垃圾信息
UnifoLM-VLA-0:宇树科技开源的通用视觉-语言-动作大模型
LingBot-World官网:蚂蚁灵波科技开源的交互式世界模型
LingBot-Depth:专为攻克机器人在透明、反光物体场景的AI模型
上面是“lingbot-VA:全球首个面向通用机器人控制的因果视频-动作世界模型”的全面内容,想了解更多关于 IT知识 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_30355.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 Makeform官网:一个免费AI表单构建工具,通过聊天快速生成定制表单
Makeform官网:一个免费AI表单构建工具,通过聊天快速生成定制表单 让Dedecms自带搜索实现全文检索
让Dedecms自带搜索实现全文检索 推荐一款优设网免费可商用字体——优设标题黑体
推荐一款优设网免费可商用字体——优设标题黑体 Soolo AI:面向独立创业者、小企业及创意工作室的AI品牌建设工具
Soolo AI:面向独立创业者、小企业及创意工作室的AI品牌建设工具