
在当今的大数据时代,网络爬虫变得越来越重要,因为它可以找到大量的信息并分析数据。网络爬虫主要用于收集网站内容。下面web建站小编给大家简单介绍一下!
具体语法如下:
<?php
// 定义URL
$startUrl = "https://ipkd.cn";
$depth = 2;
// 放置已经处理的URL和当前的深度
$processedUrls = [
$startUrl => 0
];
// 运行爬虫
getAllLinks($startUrl, $depth);
//获取给定URL的HTML
function getHTML($url) {
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($curl);
curl_close($curl);
return $html;
}
//获取所有链接
function getAllLinks($url, $depth) {
global $processedUrls;
if ($depth === 0) {
return;
}
$html = getHTML($url);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$links = $dom->getElementsByTagName('a');
foreach ($links as $link) {
$href = $link->getAttribute('href');
if (strpos($href, $url) !== false && !array_key_exists($href, $processedUrls)) {
$processedUrls[$href] = $processedUrls[$url] + 1;
echo $href . " (Depth: " . $processedUrls[$href] . ")" . PHP_EOL;
getAllLinks($href, $depth - 1);
}
}
}
php删除接口:在指定的数据库数据表中根据ID删除指定的数据
上面是“如何利用php语法编写web爬虫程序”的全面内容,想了解更多关于 php入门 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_4698.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 织梦cms如何解决会员审核后积分/金币才增加
织梦cms如何解决会员审核后积分/金币才增加 百灵无损音乐:一个免费音乐资源站,可以在线播放及下载
百灵无损音乐:一个免费音乐资源站,可以在线播放及下载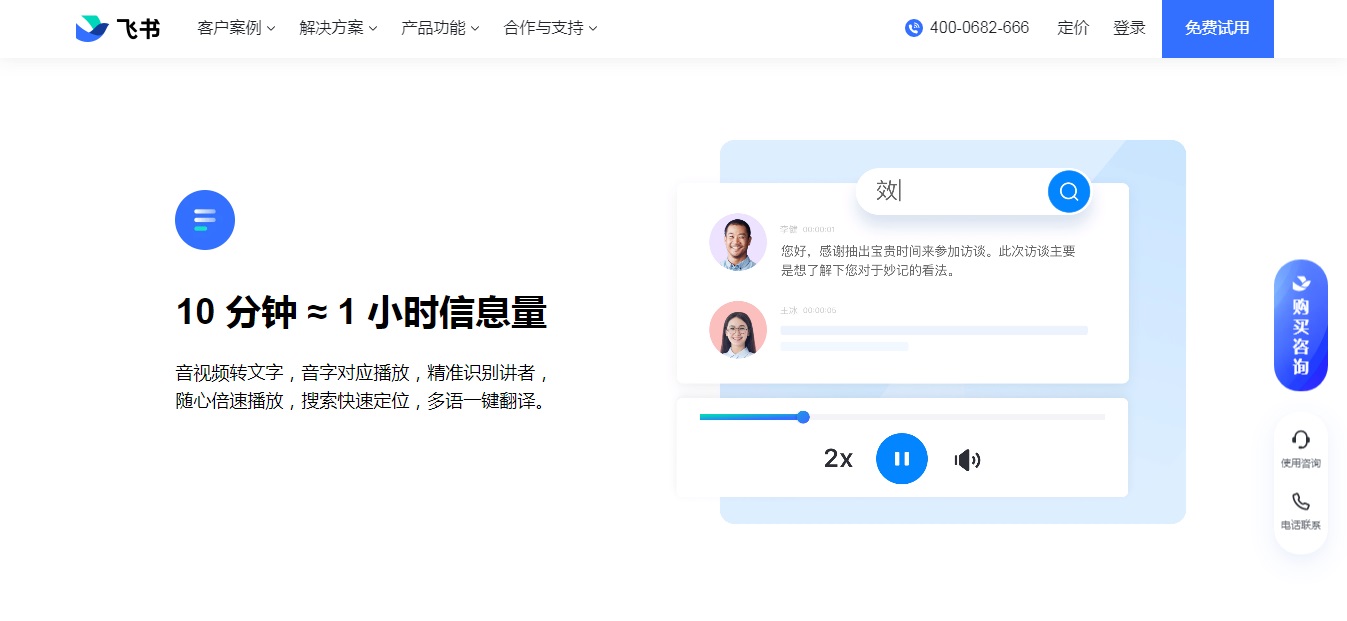 推荐一款免费的语音识别转文字在线工具——飞书妙记
推荐一款免费的语音识别转文字在线工具——飞书妙记