
LLaDA(Large Language Diffusion with Masking)是由中国人民大学高瓴人工智能研究院与蚂蚁集团联合推出的一种新型扩散语言模型。该模型通过正向掩码和反向预测机制,突破了传统自回归语言模型的限制,显著提升了语言生成和理解能力。
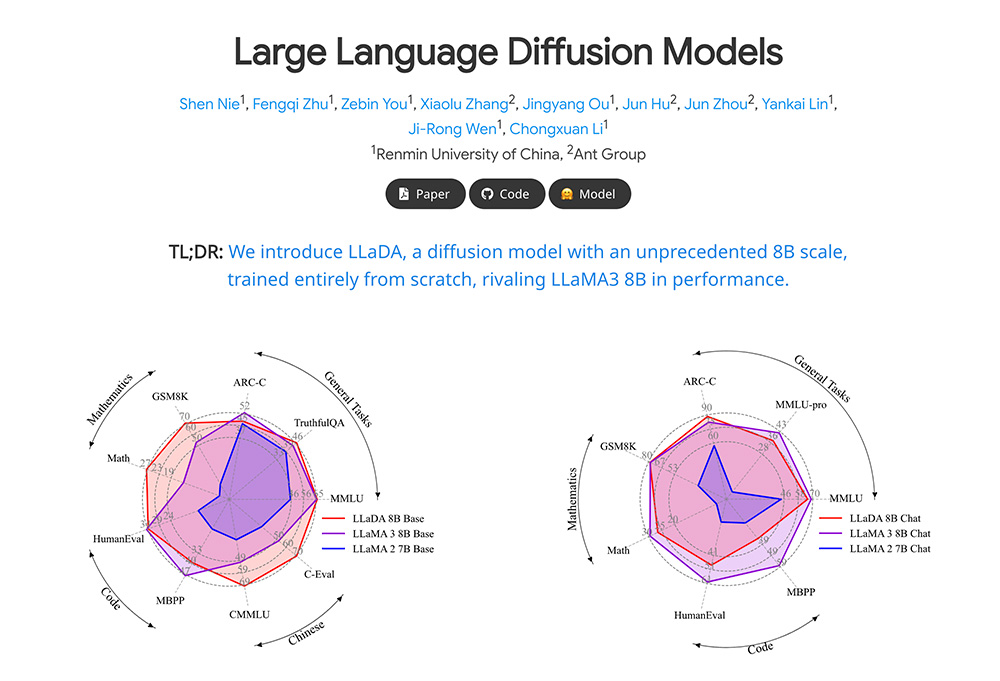
LLaDA功能特点:
1、正向掩码与反向预测:
LLaDA 采用正向掩码和反向预测机制,能够同时捕捉文本的双向依赖关系。这种机制突破了传统自回归模型(如 GPT)单向生成的局限,显著提升了模型在逆向推理任务中的表现。
2、强大的上下文学习能力:
LLaDA 在上下文学习任务中表现出色,超越了 LLaMA2-7B,并与 LLaMA3-8B 表现相当。其在零样本和少样本学习任务中展现了卓越的性能。
3、高效的指令遵循能力:
通过监督微调(SFT),LLaDA 显著增强了指令遵循能力,尤其在多轮对话任务中表现出色。
4、卓越的反转推理能力:
LLaDA 有效解决了传统模型在逆向任务中的“反转诅咒”问题,特别是在反转诗歌完成任务中,其表现优于 GPT-4o。
5、高效的训练与扩展性:
LLaDA 在 2.3 万亿 tokens 的数据上进行预训练,仅使用 13 万 H800 GPU 时,展现出高效的训练性能。它能够扩展到 10²³ FLOPs 的计算资源上,并在多个基准测试中与自回归基线模型相当。
6、随机掩码机制:
LLaDA 采用随机掩码机制,对输入序列中的 token 进行动态掩码处理,相比传统的固定掩码比例(如 BERT 中的 15%),其在大规模数据上表现更优。
7、灵活的 Transformer 架构:
LLaDA 使用 Transformer 架构作为掩码预测器,不使用因果掩码(Causal Mask),能够同时看到输入序列中的所有 token,从而更好地捕捉文本的双向依赖关系。
LLaDA应用场景:
1、自然语言处理:在语言理解、数学、代码和中文等多样化任务中表现出色。
2、多轮对话系统:通过监督微调,LLaDA 在多轮对话任务中展现了强大的指令遵循能力。
3、逆向推理任务:特别适用于需要逆向推理的任务,如反转诗歌生成。
LLaDA相关地址:
1、 LLaDA项目官网:https://ml-gsai.github.io/LLaDA
2、GitHub仓库:https://github.com/ML-GSAI/LLaDA
3、arXiv技术论文:https://arxiv.org/pdf/2502.09992
DeepSeek-V4模型 - 包含deepseek-v4-pro和deepseek-v4-flash两个版本,拥有百万字超长上下文窗口
Steerling-8B模型使用入口,80亿参数规模,在1.35万亿Token语料上训练完成
Ming-omni-tts音频生成模型官网使用入口,优于SeedTTS、GLM-TTS
Ming-omni-tts模型官网使用入口,大幅提升推理效率,推理帧率可低至3.1Hz,有效降低延迟
Ring-2.5-1T模型魔塔使用入口,蚂蚁集团开源万亿参数思维模型
上面是“人大高瓴AI联合蚂蚁推出LLaDA,打破大语言模型“逆诅咒””的全面内容,想了解更多关于 IT知识 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_17368.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 帝国cms教程封面模板调用栏目别名
帝国cms教程封面模板调用栏目别名 国家标准全文公开系统官网首页入口
国家标准全文公开系统官网首页入口 笔尖AI写作工具官网,一款适用于多种类型的写作工具
笔尖AI写作工具官网,一款适用于多种类型的写作工具 Speechki
Speechki vuejs配置文件中出现的^与~代表什么意思
vuejs配置文件中出现的^与~代表什么意思