
OSUM是由西北工业大学 ASLP 实验室开发的开源语音理解模型,旨在探索在有限的学术资源下如何高效训练和利用语音理解模型,以推动相关技术的研究与创新。该模型结合了 Whisper 编码器和 Qwen2 语言模型,支持多种语音任务,并通过 ASR+X 训练策略优化多任务学习。
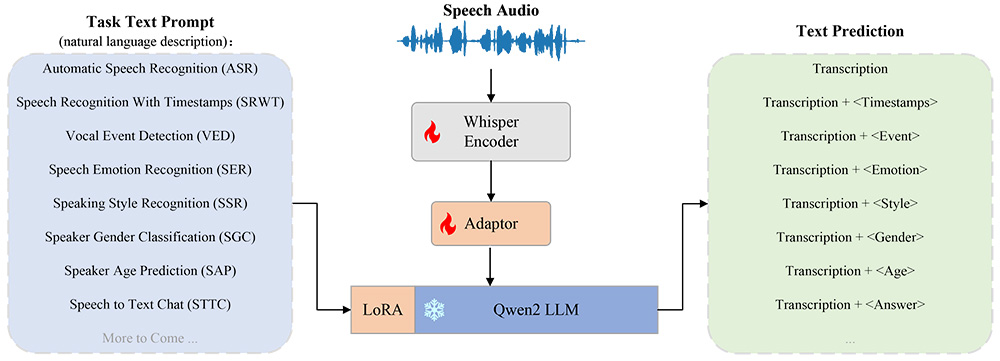
OSUM功能特点:
1、多任务支持:
OSUM 支持 8 种语音任务,包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话人性别分类(SGC)、说话人年龄预测(SAP)以及语音转文本聊天(STTC)。
2、高效多任务训练:
采用 ASR+X 训练策略,同时优化模态对齐和目标任务,实现高效稳定的多任务训练。
3、数据透明性:
训练方法和数据准备过程均已开放,为学术界提供参考。
4、性能提升:
技术报告 v2.0 显示,训练数据量增至 50.5K 小时,模型性能显著提升。
5、开源许可:
代码和权重在 Apache 2.0 许可下开放,可用于学术和商业目的。
SoulX-Singer模型官网使用入口,工业级零样本歌声合成模型
VoiceSculptor:西北工业大学、语图智能等机构推出的音色设计模型
上面是“一款由西北工业大学 ASLP 实验室开发的开源语音理解模型——OSUM”的全面内容,想了解更多关于 IT知识 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_17556.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 GenFlow超能搭子:极速生成PPT、报告、图表、海报等全模态内容
GenFlow超能搭子:极速生成PPT、报告、图表、海报等全模态内容 The Boring Company:一家由埃隆·马斯克创立的隧道挖掘初创企业
The Boring Company:一家由埃隆·马斯克创立的隧道挖掘初创企业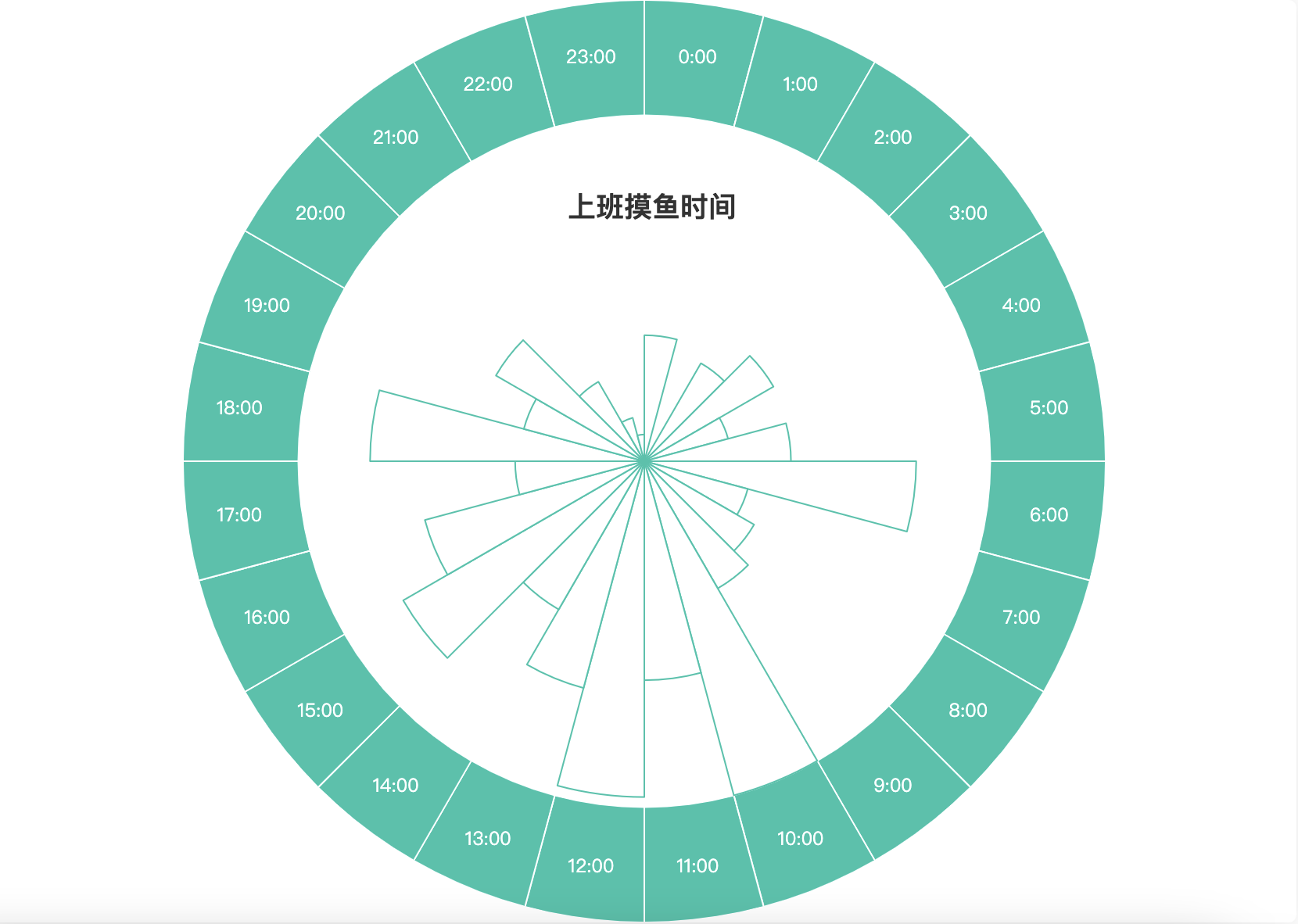 百度echarts利用南丁格尔图做一个上班摸鱼时间分布图
百度echarts利用南丁格尔图做一个上班摸鱼时间分布图