
DeepEP是由 DeepSeek 团队开源的首个专为混合专家(MoE)模型训练和推理设计的高效专家并行(EP)通信库。它旨在通过优化通信效率,显著提升大规模模型训练和推理任务的性能。
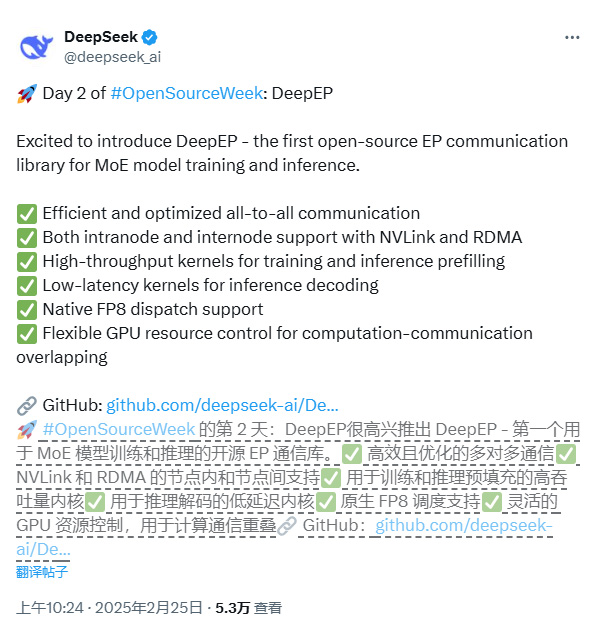
DeepEP功能特点:
1、高效通信内核:
提供高吞吐量和低延迟的全对全(all-to-all)GPU 内核,适用于 MoE 分发和合并操作。
2、低精度支持:
支持 FP8 和 BF16 等低精度运算,提升计算效率并节省显存。
3、优化的内核设计:
针对 NVLink 和 RDMA 的非对称带宽转发场景进行了深度优化,确保高吞吐量表现。
4、低延迟推理解码:
提供纯 RDMA 的低延迟内核,延迟低至163微秒,适用于延迟敏感的推理解码任务。
5、灵活的 GPU 资源控制:
支持计算与通信的重叠,不占用 GPU SM 资源,最大化计算效率。
6、硬件优化:
利用未公开的 PTX 指令提升 Hopper 架构的性能,支持 InfiniBand 网络。
7、高性能表现:
在 H800 GPU 上测试,最大带宽可达153 GB/s(NVLink)和46 GB/s(RDMA)。
DeepEP应用场景:
1、大规模模型训练:适用于 MoE 模型的训练,提供高效的并行通信支持。
2、推理任务:特别适合延迟敏感的推理解码场景,显著提升效率。
3、高性能计算:适配现代高性能计算需求,支持多种硬件平台。
DeepEP使用与集成:
1、环境要求:需要 Python 3.8+、CUDA 12.3+ 和 PyTorch 2.1+。
2、安装与使用:开源且易于集成,只需几行命令即可构建并运行测试。
Nemotron-Cascade 2模型官网 - 英伟达正式开源的MoE混合专家模型,总参数量达30B
LongCat-Flash-Prover模型官网 - 美团开源的5600亿参数MoE形式化数学推理模型
ZenMux:全球首个搭载保险赔付机制的企业级AI大模型聚合平台
Lorka AI:汇聚GPT、Gemini、DeepSeek等于一体的多模型聚合人工智能平台
Qwen3-Coder-Next:阿里开源的MoE架构编程智能体模型
上面是“DeepEP:DeepSeek推出的首个(EP)通信库,助力大规模MoE模型训练与推理”的全面内容,想了解更多关于 IT知识 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_17978.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 一张图带你了解JS的各种循环遍历方法
一张图带你了解JS的各种循环遍历方法 js如何利用setTimeout实现倒计时
js如何利用setTimeout实现倒计时 一款DeepSeek公司推出的高性能推理模型预览版——DeepSeek-R1-Lite-Preview
一款DeepSeek公司推出的高性能推理模型预览版——DeepSeek-R1-Lite-Preview Agnes AI:实现多人实时编辑文档、报告或PPT制作
Agnes AI:实现多人实时编辑文档、报告或PPT制作 Windrecorder(捕风记录仪):开源本地屏幕录制与智能检索工具
Windrecorder(捕风记录仪):开源本地屏幕录制与智能检索工具