
TokenSwift是一个创新的框架,旨在显著加速大语言模型(LLMs)的超长文本生成任务。它通过优化生成过程,解决了传统自回归(AR)方法在生成超长文本时面临的瓶颈,如频繁的模型加载、动态KV缓存管理和重复性生成问题。
TokenSwift功能特点:
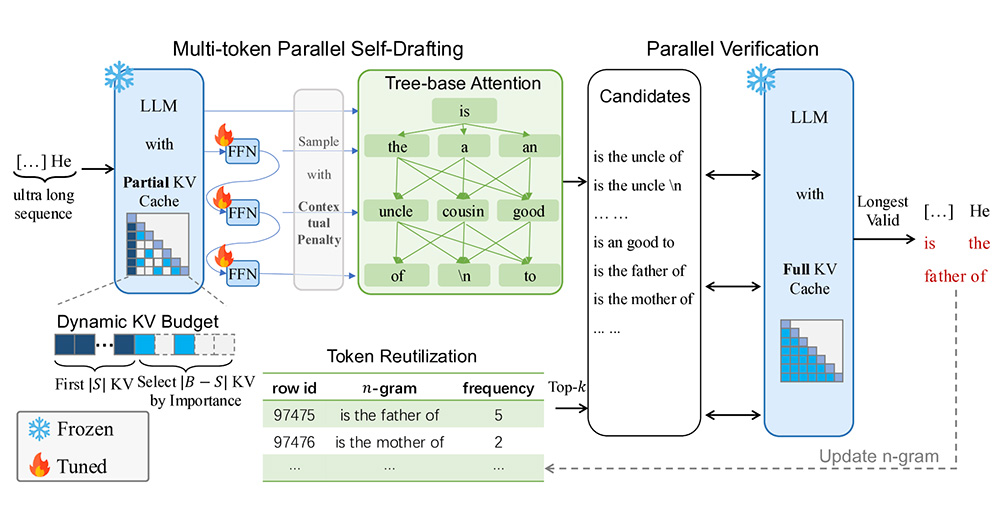
1、多Token并行生成与Token复用:
TokenSwift借鉴了Medusa等方法,通过引入额外的线性层,使模型在一次前向传播中能够同时生成多个草稿Token。基于生成文本中的n-gram频率信息,系统会自动检索并复用高频短语,减少模型重新加载的次数,提升整体效率。
2、动态KV缓存更新策略:
TokenSwift采用动态更新策略管理KV缓存。在生成过程中保留初始KV缓存,同时根据Token的重要性对后续缓存进行有序替换,有效控制缓存规模并确保关键信息始终被保存,降低因缓存加载带来的延迟。
3、基于树结构的多候选Token验证:
为保证生成结果与目标模型预测的一致性,TokenSwift引入了树形注意力机制。通过构建包含多个候选Token组合的树形结构,并采用并行验证的方式,从中随机选择最长且有效的n-gram作为最终输出,确保生成过程无损且多样性得到提升。
4、上下文惩罚策略:
为抑制重复生成问题,TokenSwift设计了一种上下文惩罚方法。在生成过程中为近期生成的Token施加惩罚,使得模型在选择下一Token时更倾向于多样化输出,从而有效减少重复现象。
TokenSwift应用场景:
1、内容创作:
TokenSwift可用于生成长篇小说、剧本、研究报告等,显著提高创作效率。
2、智能客服:
在需要实时生成长文本回答的场景中,TokenSwift可以快速生成高质量的回复,提升用户体验。
3、教育领域:
用于生成教学材料、考试题目和答案解析,帮助教师和学生更高效地准备和学习。
4、企业级应用:
在需要快速生成长文本报告、产品说明等场景中,TokenSwift可以显著节省时间和资源。
DeepSeek-V4模型 - 包含deepseek-v4-pro和deepseek-v4-flash两个版本,拥有百万字超长上下文窗口
Steerling-8B模型使用入口,80亿参数规模,在1.35万亿Token语料上训练完成
TeichAI官网使用入口,面向企业与开发者的一站式人工智能能力平台
Open Coding Agents:低成本、可复现的开源编程智能体,支持任意私有代码库
LongCat-Flash-Lite官网:美团新一代高效大语言模型
上面是“一款90分钟内生成10万Token,相比传统方法提速3倍以上的AI框架——TokenSwift”的全面内容,想了解更多关于 IT知识 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_18433.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 Parallel Live
Parallel Live 盘点各种时髦又可爱的宝宝小名(奶凶奶凶的女宝宝)
盘点各种时髦又可爱的宝宝小名(奶凶奶凶的女宝宝) CopyWeb:一款功能强大且高效的AI驱动网页设计转换工具
CopyWeb:一款功能强大且高效的AI驱动网页设计转换工具 Shazam
Shazam