
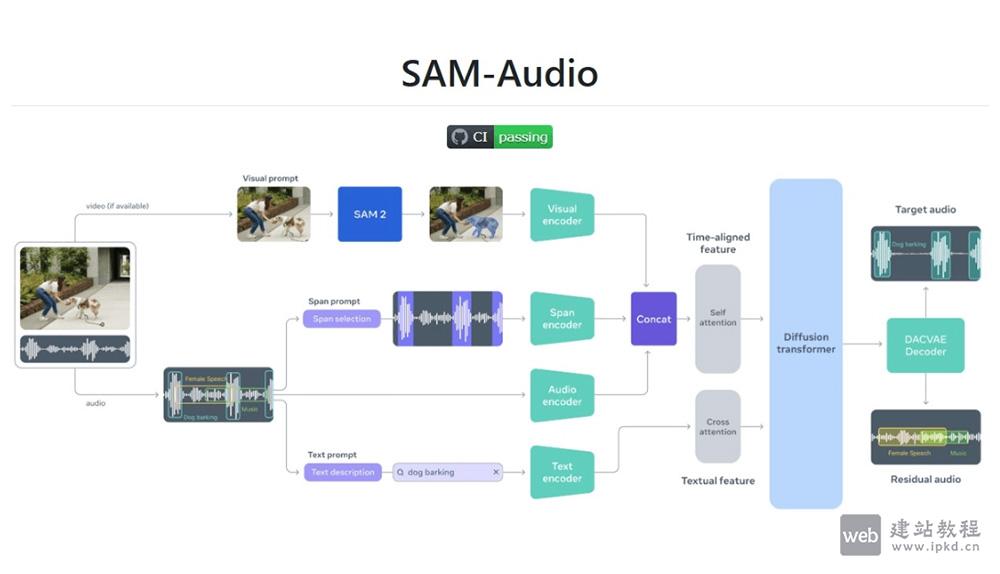
SAM Audio是Meta推出的开源音频分割模型,延续其感知智能技术优势,核心依托Perception Encoder Audiovisual(PE-AV)视听融合架构,支持文本、视觉、时间片段等多模态提示输入,能从复杂音频混合中精准分离特定声音。模型兼具实时处理能力与高精度分离效果,搭配专属无参考评测工具与真实环境基准测试,为音频编辑、创意制作、无障碍技术等场景提供高效解决方案,推动音频AI的实用化与包容性发展。
SAM Audio核心优势:
1、多模态提示灵活适配:
打破单一输入限制,支持文本描述(如“吉他声”“交通噪声”)、视频视觉点选(点击发声物体)、时间片段标记三种提示方式,用户可根据场景灵活选择,降低操作门槛。
2、视听融合+精准时序,分离精度高:
PE-AV架构融合逐帧视频特征与音频表示,实现视听信息精准对齐与时间标注,即使在复杂混合音频中,也能精准锁定目标声音,避免分离偏差。
3、高效实时处理,适配大规模场景:
实时因子约为0.7,运行速度快于实时处理,无需长时间等待即可完成音频分离,适合批量音频处理或实时应用场景。
4、全场景覆盖+鲁棒性强:
经大规模多模态数据训练,涵盖语音、音乐、通用音效等多种声音类型,能适配真实环境中的复杂音频场景,泛化能力突出。
5、生态完善,评测与基准兼备:
配套SAM Audio Judge无参考评测模型(无需参考音轨即可客观评估分离质量)与SAM Audio-Bench真实环境基准测试,确保模型在实际应用中的有效性与可靠性。
SAM Audio核心功能:
1、多模态提示音频分离:
通过文本描述、视频视觉选择、时间片段标记任意一种或多种提示,从混合音频中精准分离目标声音(如人声、乐器声、特定噪声)。
2、全类型音频任务支持:
兼容语音分离、音乐乐器提取、通用音效分离等多元任务,适配播客清理、歌曲混音、视频配音等不同场景需求。
3、无参考音频质量评测:
内置SAM Audio Judge评测工具,基于人类感知维度评估分离质量,无需原始参考音轨,提供贴近实际听觉体验的客观标准。
4、真实环境基准验证:
配套SAM Audio-Bench基准测试(首个真实环境音频分离基准),覆盖多音频领域与提示类型,确保模型在实际场景中的鲁棒性。
5、高效实时处理:
实时因子约0.7,处理速度超越音频时长本身,支持大规模批量处理与实时应用部署,兼顾效率与体验。
6、无障碍技术适配:
预留技术接口,支持与听力辅助设备集成,为无障碍场景提供定制化音频分离能力。
SAM Audio技术原理:
1、PE-AV视听融合架构:
基于Meta Perception Encoder模型拓展,提取逐帧视频视觉特征并与音频表示精准对齐,融合视听语义信息与时间标注,为目标声音定位提供双重支撑,提升分离精度。
2、流匹配扩散Transformer:
采用生成式建模框架,将混合音频与多模态提示编码为共享特征表示,通过扩散模型生成目标音轨与剩余音轨,实现端到端精准分离,兼容多种提示模态输入。
3、大规模多模态训练:
融合真实场景混合音频与合成数据,覆盖语音、音乐、通用音效等丰富声音事件,结合先进音频合成策略,强化模型对复杂环境、多样声音类型的适配能力。
4、无参考评测技术:
SAM Audio Judge通过学习人类听觉感知规律,从清晰度、完整性等维度构建评测体系,无需原始参考音轨即可客观评估分离质量,解决传统评测依赖参考音的局限性。
SAM Audio应用场景:
1、音频清理与降噪:
去除播客、录音、会议音频中的背景噪声(如交通声、宠物叫声、环境杂音),提升音频清晰度,适配内容创作、办公记录等场景。
2、创意媒体与音乐制作:
从歌曲中分离人声、吉他、钢琴等特定乐器音轨,支持音频重新混音、二次创作;也可提取影视片段中的特定音效,为创意制作提供素材支持。
3、无障碍与听力辅助:
与助听器、听力辅助设备集成,精准分离人声与环境噪声,帮助听力受损人群聚焦核心音频内容,提升听觉理解效果。
4、视频编辑与后期制作:
在视频剪辑中,通过点选视频中的发声对象(如歌手、乐器、交通工具)分离对应声音,灵活调整音轨搭配,提升视频后期制作的灵活性与效率。
5、音频分析与科研:
为音乐分析(如乐器演奏技巧研究)、声音生态学(如自然环境中特定生物声音监测)、语音研究等领域提供精准分离工具,助力学术研究与数据挖掘。
Facebook推出三款AI全新功能——动态头像、Stories与照片重塑工具
Omnilingual ASR:Meta AI推出的千亿级语言自动语音识别系统
CWM:Meta开源320亿参数代码世界模型,重构AI代码生成新范式
Meta ARE:Meta出品,面向AI Agents的动态模拟研究与评估平台
Audio2PhotoReal:Meta AI重磅技术,音频直驱超写实全身虚拟人物生成
上面是“SAM Audio:Meta开源多模态音频分割模型,精准分离复杂声音场景”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_25485.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 什么是SMTP协议?有什么作用?
什么是SMTP协议?有什么作用? City-Roads官网:开源免费的城市道路网可视化工具
City-Roads官网:开源免费的城市道路网可视化工具 问小白
问小白 PhotoKit图片编辑器:在线图片编辑工具,无需下载即可使用
PhotoKit图片编辑器:在线图片编辑工具,无需下载即可使用