
Qwen3-ASR是阿里云通义千问团队开源的语音识别模型系列,包含1.7B高精度版、0.6B高效版两款ASR模型,及专用Qwen3-ForcedAligner-0.6B强制对齐模型。模型支持52个语种与方言识别、流式/非流式一体化推理,在强噪声、快语速、歌唱等复杂场景下表现稳定鲁棒——1.7B模型在中英文及方言识别领域达开源SOTA水平,0.6B模型可支持128并发、2000倍吞吐,10秒即可处理5小时音频,兼顾精度与效率需求。
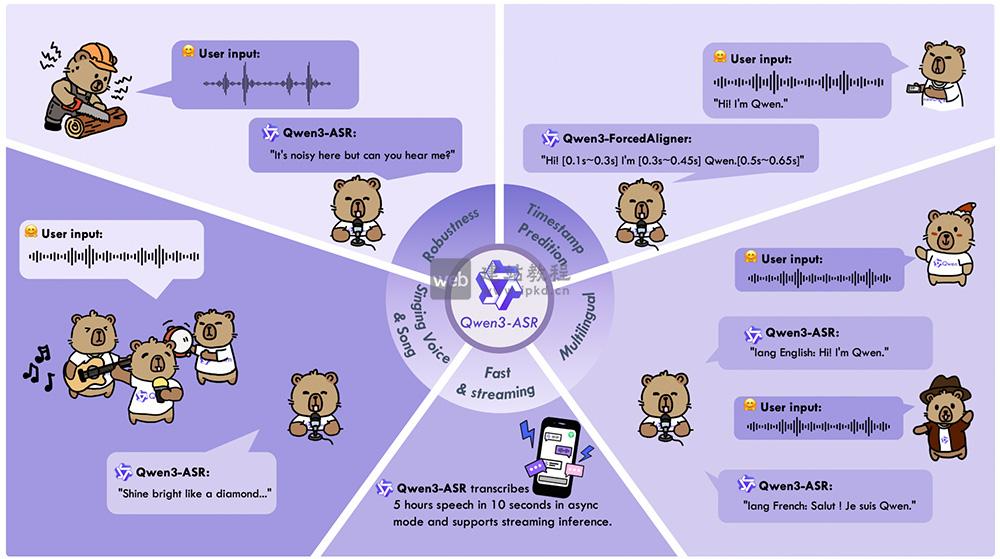
Qwen3-ASR的主要功能:
1、多语种全域识别:
支持30个主要语种的语音识别与语种自动识别,实现多语言统一建模,适配跨语言场景需求。
2、广覆盖方言识别:
覆盖粤语、吴语、闽南语及各省地方口音等22种中文方言,解决方言语音识别痛点。
3、跨地域口音适配:
针对16个国家/地区的英文口音差异做专项优化,显著提升跨地域英文语音的识别准确率。
4、流式/非流式双模推理:
支持流式与非流式一体化推理,最长可一次性处理20分钟音频,兼顾实时性与长音频处理需求。
5、复杂场景强鲁棒:
具备强抗干扰能力,可稳定应对强噪声、低音质、快语速及老人/儿童非标准语音等复杂场景。
6、歌唱内容转写:
支持带背景音乐的歌唱语音识别,可完整转写整首中英文歌曲,适配娱乐、音乐相关场景。
7、精准时间戳对齐:
提供词级/句级时间戳对齐功能,精准匹配语音与文本位置,满足字幕生成、音频编辑等场景需求。
Qwen3-ASR的技术原理:
1、创新语音编码层:
采用预训练AuT语音编码器提取高层声学表征,替代传统Fbank特征,大幅增强模型对噪声、口音的泛化能力,提升复杂环境下的识别稳定性。
2、多模态基座架构:
基于Qwen3-Omni多模态大模型构建,借助其跨模态理解能力实现“语音-文本”直接映射,摒弃传统HMM/GMM流水线,简化技术链路的同时提升识别精度。
3、分层训练范式:
先通过大规模多语种预训练建立通用声学语义空间,再针对方言、歌唱、噪声等细分场景进行细粒度微调,联合优化语种识别与语音识别双任务,兼顾通用性与场景适配性。
4、高效推理优化:
0.6B模型集成vLLM加速引擎,支持批量推理与异步服务,128并发下可实现2000倍吞吐;流式版本采用分块缓存机制,在实时响应与识别准确率间实现最优平衡。
5、高精度强制对齐:
Qwen3-ForcedAligner基于非自回归LLM架构,通过并行解码快速预测时间戳,单并发RTF(实时率)低至0.0089,精度超越传统CTC与WhisperX方案,满足高精度对齐需求。
Qwen3-ASR的应用场景:
1、智能会议转写:
实时转写多人混合会议内容,支持中英文混杂、多方言口音识别,自动生成带词级时间戳的会议纪要,大幅降低会后整理成本。
2、全场景视频字幕:
为影视剧、短视频、直播等生成精准字幕,支持带背景音乐的歌唱内容识别,可扩展多语种翻译字幕制作,适配娱乐、传媒领域需求。
3、电话客服交互:
在强噪声、低音质的通话环境下稳定识别客户语音,支持实时流式转写与关键词提取,辅助客服快速抓取客户需求、优化服务效率。
4、智能家居交互:
适配老人、儿童等非标准发音,支持远场拾音与方言语音交互,解决传统智能音箱“听不懂”方言、非标准语音的问题,提升家居语音控制体验。
5、法律取证核验:
对庭审录音、取证音频等复杂声学环境下的录音证据进行高精度转写,提供可追溯的词级时间戳,为庭审举证、内容核验提供可靠文本依据。
Qwen3.6-Plus编程模型 - 阿里通义重磅Agent编程模型,百万上下文+超强编码智能体
Fun-CineForge模型使用入口,通义实验室开源的影视级多模态配音大模型
Mobile-Agent-v3.5模型使用入口,开源多平台GUI Agent框架
Fun-CosyVoice3.5语音生成模型,支持13种语言,可精准调节语气、语速、语调、情绪
Fun-AudioGen-VD模型使用入口,专注于专业声音设计与场景化音频生成
上面是“Qwen3-ASR:阿里云通义千问团队开源的语音识别模型系列”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_29456.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 Colorify AI:AI图像上色工具,将文本或照片快速转换为高质量的涂色页
Colorify AI:AI图像上色工具,将文本或照片快速转换为高质量的涂色页 图司机官网:在线一键搞定设计、印刷并能在线图片编辑
图司机官网:在线一键搞定设计、印刷并能在线图片编辑 html前端中有哪些base64文件前缀
html前端中有哪些base64文件前缀 Skyanime官网使用入口,SkyReels视频大模型打造的AI短剧创作工具
Skyanime官网使用入口,SkyReels视频大模型打造的AI短剧创作工具 Infermedica:利用机器学习技术为症状检查聊天工具
Infermedica:利用机器学习技术为症状检查聊天工具