
Audio2Face是英伟达推出的AI驱动3D面部动画生成工具,能够根据任意语音音轨,快速生成匹配情绪与节奏的逼真面部动画。它大幅简化 3D角色动画制作流程,适用于游戏开发、影视制作、实时数字助理等多元场景,既可以作为交互式实时应用工具,也能胜任传统面部动画创作工作。
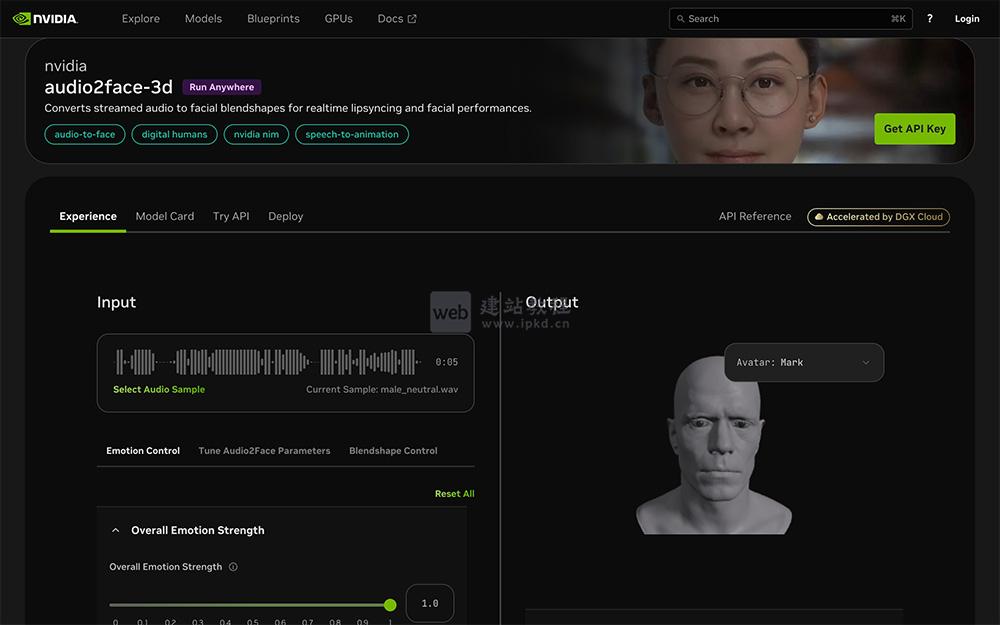
Audio2Face核心工作原理:
1、开箱即用的角色支持:
工具预装“数字标记”3D 角色模型,无需额外建模即可快速启动动画生成;
2、一键上传音频驱动:
用户只需上传目标音轨,预训练神经网络会实时分析语音的韵律、语调特征,输出对应的面部动作参数;
3、精准驱动 3D 网格顶点:
网络输出的参数直接作用于角色面部的 3D 顶点网格,生成自然的口型、表情与面部肌肉运动;
4、灵活的后处理优化:
支持调整多项后处理参数,精细化打磨角色表演效果;官方展示的多数案例,均为工具原始输出,几乎无需额外编辑。
Audio2Face多元应用场景:
1、多语言无缝适配:
轻松处理英语、法语、意大利语、俄语等多种语言的语音音轨,且语言库持续更新扩展,满足全球化内容创作需求。
2、交互式聊天机器人开发:
在 GTC Spring 2020 上亮相的 Misty 天气机器人,正是基于 Audio2Face 实现实时面部动画驱动。该工具支持从逼真人类网格到风格化角色网格的动作重定向,可快速打造交互式服务代理。
3、3D 内容创作民主化:
曾在 GeForce 30 系列发布会的 Omniverse Machinima 演示中登场。针对传统面部动画制作复杂、成本高昂的痛点,Audio2Face 实现动画全流程自动化,大幅降低 3D 内容创作门槛。
4、任意 3D 人脸的动作重定向:
可基于任意对话音轨,将动画效果迁移至不同 3D 人脸模型,无论是写实风格还是卡通风格的角色,都能精准匹配语音生成自然表情。
5、奇幻角色动画创作:
支持对奇幻生物、外星人等非人类角色进行面部动画驱动,借助“数字标记”的动作映射,让虚构角色也能呈现富有表现力的面部动态。
Nemotron-Cascade 2模型官网 - 英伟达正式开源的MoE混合专家模型,总参数量达30B
NemoClaw企业级AI Agent框架,内置Nemotron模型处理本地日常任务
Nemotron 3 Super模型使用入口,英伟达推出的1200亿参数开源AI模型
Ultralytics官网:一个轻量化开源计算机视觉与AI深度学习框架
FastBuildAI:一款面向AI开发者、创业者开源零代码AI应用开发框架
上面是“Audio2Face:英伟达AI语音秒生成高表现力3D面部动画”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_27364.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 新CG儿:一个专注于AE模板、视频素材等数字视觉分享的平台
新CG儿:一个专注于AE模板、视频素材等数字视觉分享的平台 Doclific:开发者专属本地文档管理工具,一站式搞定技术文档编写
Doclific:开发者专属本地文档管理工具,一站式搞定技术文档编写 css3加载中loading效果代码
css3加载中loading效果代码 Mistral AI:欧洲开源大模型标杆企业,提供了增强的推理、理解和概括
Mistral AI:欧洲开源大模型标杆企业,提供了增强的推理、理解和概括