
Qwen3-LiveTranslate是阿里通义团队研发的大语言模型驱动型多语言实时音视频同传系统,支持18种主流语言及多地方言的精准翻译,创新性融合视觉增强技术,通过捕捉口型、动作等多模态信息,大幅提升复杂场景下的翻译准确性。凭借最低3秒的低延迟表现与无损同传技术,模型实现了媲美离线翻译的高水准译文质量,搭配自然拟人化音色输出,即便在复杂声学环境中也能稳定发挥,真正跨越语言鸿沟,让跨语言交流流畅无阻。
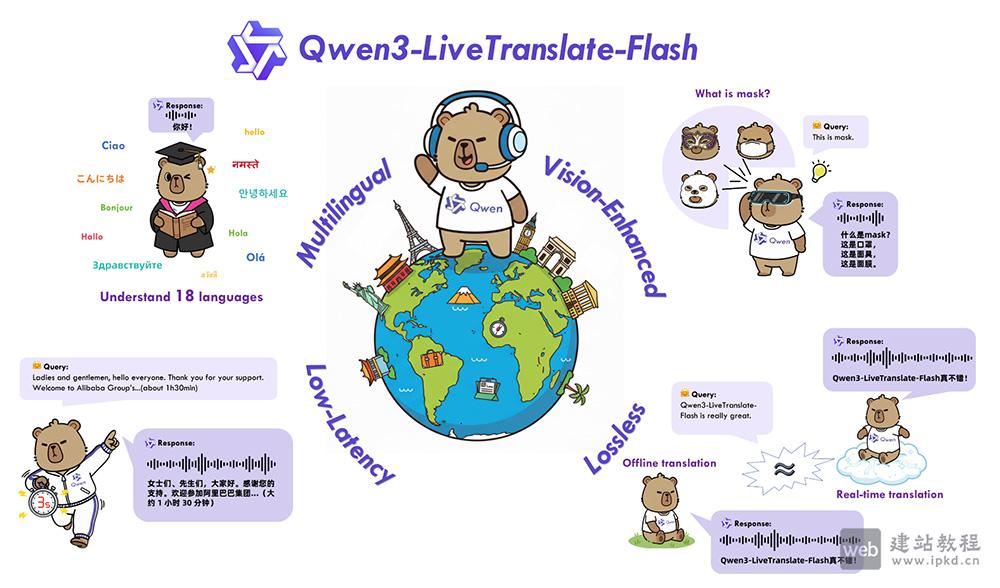
Qwen3-LiveTranslate核心功能:
1、多语言多方言全覆盖翻译:
支持中、英、法、德、日、韩等18种主流语言,以及普通话、粤语、四川话等多地方言的双向互译,覆盖离线翻译与实时音视频同传双场景,满足全球化沟通的多元需求。
2、视觉增强提升翻译精准度:
创新性融合口型、肢体动作、画面文字等视觉上下文信息,有效解决嘈杂环境下语音识别模糊、一词多义歧义等痛点,显著提升翻译的准确性与鲁棒性。
3、低延迟实时同传响应:
基于轻量混合专家架构与动态采样策略优化,实现最低3秒的极速延迟,打破传统同传的等待壁垒,确保跨国会议、实时直播等场景下的沟通节奏不中断。
4、无损级翻译质量输出:
依托语义单元预测技术,精准攻克跨语言语序调整难题,译文流畅度、准确度全面接近离线翻译水平,避免生硬直译导致的信息偏差。
5、自然拟人化音色适配:
可根据原始语音的语气、情绪自适应调节输出音色,生成自然流畅的拟人化语音,兼顾翻译专业性与听觉舒适度,提升沟通体验。
Qwen3-LiveTranslate技术原理:
1、多模态数据融合架构:
深度整合语音信号与视觉信息(口型、动作、文本),构建多维度输入的统一建模框架,让模型能够从“听”“看”双重维度理解语义,提升复杂场景下的翻译稳定性。
2、语义单元预测技术:
突破传统逐词翻译的局限,通过分析语言的语义结构单元,提前预测跨语言翻译中的语序调整逻辑,确保译文既符合目标语言表达习惯,又完整保留原始语义。
3、轻量混合专家架构:
采用轻量化混合专家(MoE)模型设计,结合动态采样策略智能分配计算资源,在保证翻译质量的同时,大幅降低模型推理延迟,适配实时音视频传输的低延迟要求。
4、海量音视频数据训练底座:
基于大规模多语言、多方言音视频数据集开展训练,覆盖不同口音、语速、声学环境的真实场景,让模型具备极强的泛化能力,从容应对多样化的实际沟通需求。
Qwen3-LiveTranslate应用场景:
1、国际会议同传:
为跨国研讨会、商务峰会提供实时多语言同传服务,消除语言隔阂,确保参会者高效捕捉会议核心信息,提升沟通协作效率。
2、远程教育互通:
将教师授课内容实时翻译成学生母语,打破地域与语言限制,助力全球学生共享优质教育资源,实现无障碍学习。
3、跨国商务沟通:
支撑国际商务谈判、远程视频会议的实时翻译,精准传递合作细节,避免因语言误解造成的商业损失,推动跨境业务高效开展。
4、旅游出行服务:
为出境游客提供实时语音翻译支持,帮助游客与当地人顺畅交流,解决问路、购物、就餐等场景的语言难题,提升出行体验。
5、媒体直播传播:
为国际新闻报道、体育赛事直播提供多语言实时同传,让全球观众同步收看直播内容,助力媒体内容的全球化传播。
Qwen3.6-Plus编程模型 - 阿里通义重磅Agent编程模型,百万上下文+超强编码智能体
daVinci-MagiHuman音视频生成模型 - 模型采用150亿参数的单流Transformer架构
Fun-CineForge模型使用入口,通义实验室开源的影视级多模态配音大模型
Mobile-Agent-v3.5模型使用入口,开源多平台GUI Agent框架
Fun-CosyVoice3.5语音生成模型,支持13种语言,可精准调节语气、语速、语调、情绪
标签: Qwen3基础架构, 同传大模型, 阿里通义, 音视频大模型
上面是“Qwen3-LiveTranslate:阿里通义多语言实时音视频同传模型”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_27623.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 北京鲁迅博物馆(北京新文化运动纪念馆)资料查询在线检索官网首页入口
北京鲁迅博物馆(北京新文化运动纪念馆)资料查询在线检索官网首页入口 oracle用delete误删表数据后可以恢复吗?
oracle用delete误删表数据后可以恢复吗? 超级文档:多人实时协同办公平台,高效协作零壁垒
超级文档:多人实时协同办公平台,高效协作零壁垒 2款开源的AI系统,风险智能管理系统和开源AI应用框架
2款开源的AI系统,风险智能管理系统和开源AI应用框架 AO3网页版官方入口,汇聚各种小说和原创作品网
AO3网页版官方入口,汇聚各种小说和原创作品网