
CMMLU是面向中文语境的综合性评估基准,专注衡量语言模型的中文知识储备与推理能力,覆盖67个从基础学科到高级专业的主题。其任务范畴横跨三类领域:需计算推理的自然科学、需知识沉淀的人文与社会科学、需生活常识的中国驾驶规则等场景。值得注意的是,CMMLU包含大量中国特定答案的任务,相关内容在其他地区或语言环境中不具备普适性。该基准提供丰富测试数据与性能排行榜,支持零样本(zero-shot)、五样本(five-shot)等多种评估方式,是评测中文语言模型性能的核心工具。
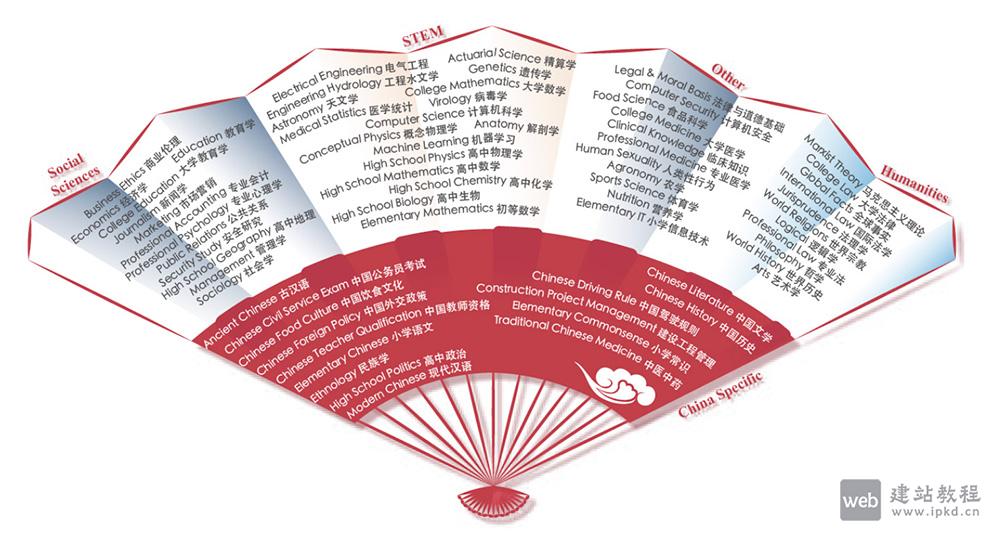
CMMLU核心功能:
1、排行榜:
呈现不同语言模型在zero-shot和five-shot测试下的性能表现,助力模型横向对比。
2、数据集:
提供开发与测试两类数据,支持快速接入与模型评估。
3、预处理代码:
配套提示生成方法,降低模型训练与测试的使用门槛。
4、评估工具:
兼容多种评估模式,便于研究者与开发者高效测试模型能力。
CMMLU使用流程:
1、获取数据集:
– GitHub下载:访问[CMMLU GitHub页面],在data目录获取开发及测试数据集。
– Hugging Face获取:访问[Hugging Face平台](https://huggingface.co/datasets/haonan-li/cmmlu),直接加载CMMLU数据集。
2、准备测试环境:
– 安装依赖:配置transformers、datasets等必要Python库。
– 克隆代码库:下载CMMLU的GitHub仓库,获取测试代码与预处理工具。
– 预处理数据:在src/mp_utils目录调用脚本,将原始数据转换为适配模型的输入格式。
3、执行模型测试:
– 加载模型:根据评估需求,部署目标语言模型及对应的tokenizer。
– 运行脚本:在script目录启动测试脚本,完成模型在多任务场景下的性能评估。
4、提交测试结果:
– 开源模型:提交拉取请求(PR),直接更新测试代码与结果数据。
– 未开放模型:将测试代码与结果发送至指定邮箱(haonan.li@librai.tech),经验证后同步至排行榜。
5、分析评估结果:
在GitHub页面的排行榜板块,查看模型在各任务的具体表现,定位模型能力的优势与短板。
CMMLU应用场景:
1、语言模型性能评估:
测试并对比不同模型在中文多任务场景下的知识与推理能力,为模型架构优化提供数据支撑。
2、教育智能辅导:
基于数据集开发智能辅导系统,为学生提供多学科练习与个性化学习建议,提升学习效率。
3、智能客服优化:
评测模型在特定领域的知识理解能力,助力智能客服系统迭代,提升服务响应质量。
4、文化知识传播:
依托数据集构建文化问答系统,传播中国文化知识,推动文化传承与推广。
5、医疗健康知识评估:
评估语言模型的医学知识储备,辅助医疗咨询工具开发,提供科学的健康参考建议。
PubMedQA:一个面向生物医学研究问题回答的专业数据集工具
H2O EvalGPT:H2O.ai推出的开源LLM大模型评估工具
LLMEval3:复旦大学NLP实验室推出的第三代中文大模型专业知识评测基准
LMArena:加州大学伯克利分校推出基于用户投票的AI模型评估平台
上面是“CMMLU:专注衡量语言模型的中文知识储备与推理能力的大模型中文评估基准”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_28230.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 网站备案和不备案的区别到底有多大
网站备案和不备案的区别到底有多大 OpenSubtitles:支持电影和电视剧的字幕搜索和多语言字幕下载服务
OpenSubtitles:支持电影和电视剧的字幕搜索和多语言字幕下载服务