
ComfyUI AudioSR是专为ComfyUI打造的原生音频超分辨率处理节点,基于先进的潜在扩散模型AudioSR研发,核心能力是将任意低质量音频(低采样率、低码率)上采样至48kHz标准音质,同时精准增强高频细节、修复压缩失真问题,实现音频清晰度、饱满度的显著提升,完美适配ComfyUI音频处理工作流。
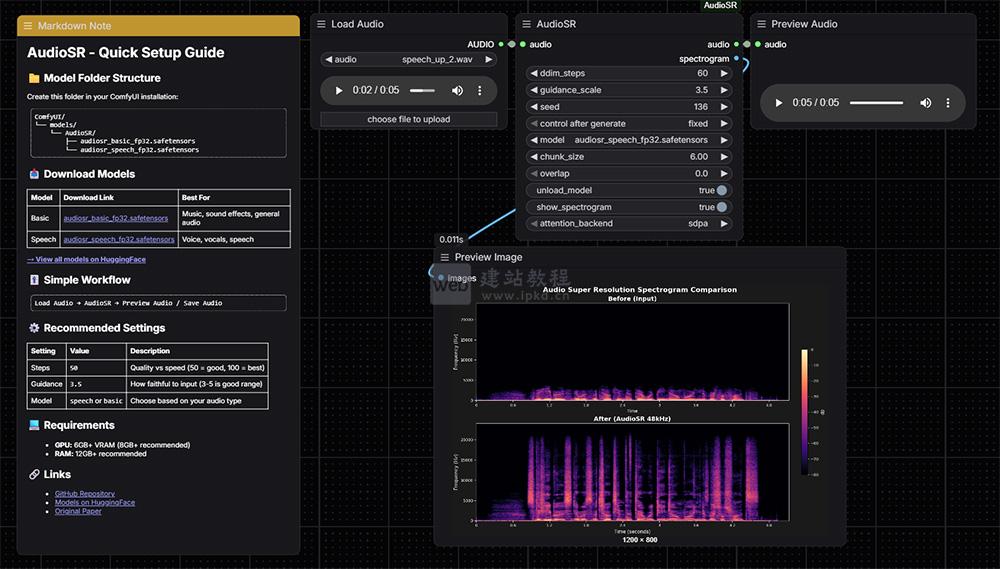
ComfyUI AudioSR功能特性:
1、专业级音频超分辨率增强:
可将低采样率、低码率的劣质音频一键上采样至48kHz标准音质,智能补充缺失的高频成分,有效修复压缩导致的失真,大幅提升音频的清晰度与饱满度,还原原声质感。
2、深度适配ComfyUI原生生态:
– 与ComfyUI官方的加载音频、预览音频、保存音频等节点无缝衔接,无需额外适配,直接嵌入现有工作流,搭建音频处理流程更简单;
– 支持ComfyUI原生中断按钮,可随时取消音频处理,操作灵活;
– 分块处理进度条实时展示,长音频处理进度可视化,过程更透明。
3、可视化对比+全场景适配:
– 内置频谱图可视化输出功能,可直观对比音频增强前后的频谱差异,频谱图自带时间轴与频率轴,频率修复效果一目了然;
– 自适应采样率处理:兼容8kHz–48kHz任意输入采样率,自动完成重采样与参数适配,无需手动调整;
– 完整声道支持:同时适配单声道、立体声音频,左右声道独立处理,保障立体声场还原;
– 超长音频无压力:采用智能分块+重叠交叉淡化机制,理论上支持无限时长音频处理,避免长音频卡顿、崩溃问题。
4、性能优化,适配多设备场景:
– 模型缓存机制:模型加载后常驻内存,重复处理音频时无需重新加载,生成速度大幅提升;
– torch.compile加速:可选开启PyTorch编译优化,推理速度提升20%–30%,缩短处理耗时;
– 灵活显存管理:支持生成后自动卸载模型,快速释放GPU显存,特别适配显存较小的消费级显卡,避免显存不足问题。
ComfyUI AudioSR安装方法:
方法 1:ComfyUI 管理器(推荐)
打开 ComfyUI Manager
搜索 AudioSR
点击安装
重启 ComfyUI
方法 2:手动安装
cd ComfyUI/custom_nodes git clone https://github.com/Saganaki22/ComfyUI-AudioSR.git cd ComfyUI-AudioSR pip install -r requirements.txt
Windows便携版嵌入式Python:
..\python_embeded\python.exe -s -m pip install -r requirements.txt
ComfyUI AudioSR插件网址入口:
1、GitHub仓库:https://github.com/Saganaki22/ComfyUI-AudioSR
2、Hugging Face模型:https://huggingface.co/drbaph/AudioSR
daVinci-MagiHuman音视频生成模型 - 模型采用150亿参数的单流Transformer架构
DataChef模型 - 上海AI Lab联合复旦大学开源的AI数据配方生成模型
Nemotron-Cascade 2模型官网 - 英伟达正式开源的MoE混合专家模型,总参数量达30B
ComfyUI-AudioX模型插件入口,多模态音频生成框架AudioX开发的专属自定义节点
Hugging Face模型库官网入口,AI模型的GitHub
标签: ComfyUI安装, github项目, HuggingFace模型库, 音频处分离
上面是“ComfyUI AudioSR插件安装入口,ComfyUI原生音频超分辨率增强节点”的全面内容,想了解更多关于 ComfyUI插件 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_31096.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 iceEditor免费开源富文本编辑器中文文档官网介绍
iceEditor免费开源富文本编辑器中文文档官网介绍 Duck.ai:一款免费、匿名的AI聊天机器人,无需用户注册账!
Duck.ai:一款免费、匿名的AI聊天机器人,无需用户注册账! 新蛋:提供超过55,000种IT数码产品电商平台
新蛋:提供超过55,000种IT数码产品电商平台 SigLIP 2:一款基于视觉语言模型PaliGemma的视觉编码器
SigLIP 2:一款基于视觉语言模型PaliGemma的视觉编码器 利用纯css3做一个风车动画效果
利用纯css3做一个风车动画效果 帝国cms的默认生成路径如何修改
帝国cms的默认生成路径如何修改