
DreamID-Omni是由清华大学与字节跳动联合研发的统一、可控、以人为中心的音视频生成框架。它打破传统AI视频工具任务割裂的局限,在单一模型内同时实现参考生成、视频编辑、音频驱动动画三大核心能力,多项指标超越主流商业闭源模型,实现了端到端统一架构的重大突破。
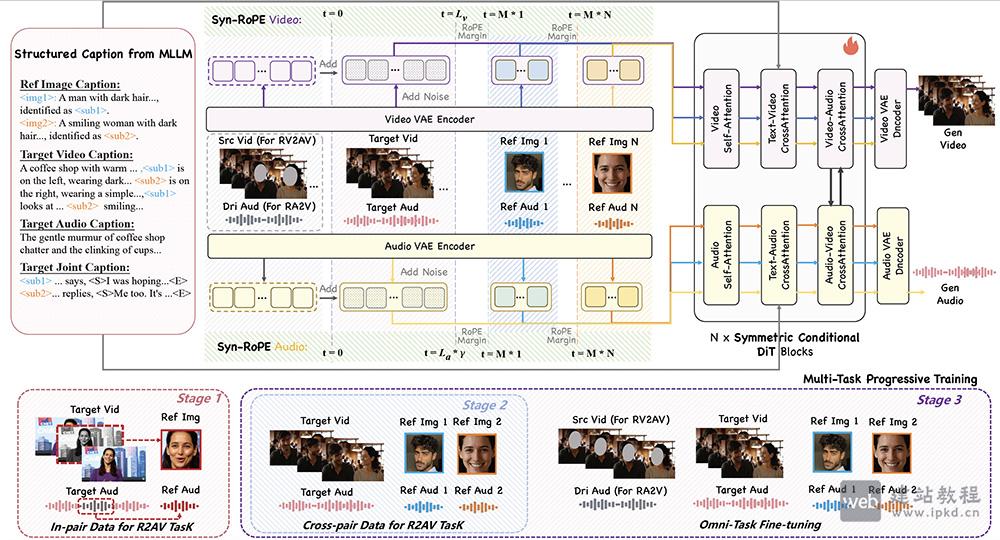
DreamID-Omni核心功能:
1、R2AV:参考生成(Reference-to-Audio-Video):
功能:输入人物参考图 + 音色参考音频 + 文本描述,直接生成音画同步的全新视频。
支持:单人 / 多人互动,每个角色可独立设定身份与声音。
应用场景:
– 虚拟主播、数字人直播内容生成
– 历史人物“复活”讲解、科普动画
– 个性化广告、定制化角色短视频
2、RV2AV:视频编辑(Reference-Video-to-Audio-Video):
功能:输入源视频 + 新人物参考(图+音频),替换视频中指定角色的身份与声音,完整保留原有动作、表情、口型。
应用场景:
– 影视/短视频快速换角、低成本二次创作
– 个性化内容定制(明星/IP换脸)
– 隐私保护:替换视频中路人面孔与声音
3、RA2V:音频驱动动画(Reference-Audio-to-Video):
功能:输入单张静态照片 + 驱动音频,让人物“动起来”,实现高精度唇形同步与自然头部姿态。
应用场景:
– 老照片开口说话、纪念视频制作
– 动态头像、AI播报员、虚拟助手
– 低成本口播视频、知识科普动画
DreamID-Omni应用场景:
1、内容创作:虚拟人、短视频、广告、影视后期快速生产。
2、教育科普:历史人物讲解、教材动画、AI讲师。
3、传媒娱乐:数字人直播、IP形象互动、个性化定制内容。
4、隐私与合规:视频人脸脱敏、路人信息保护。
5、企业与营销:品牌代言人快速替换、多语言口播视频。
seedance2pro官网 - 字节跳动推出的新一代专业级AI视频生成工具
EdgeClaw AI智能体框架使用入口,面壁智能联合清华、OpenBMB等机构推出的开源AI智能体框架
OpenMAIC官网使用入口,清华THU MAIC研发的开源AI互动教育平台
OpenMAIC官网使用入口,清华团队开源的多智能体AI课堂平台
Ctrl-World模型使用入口,厘米级轨迹精度、0.986的策略评估一致性及0.93的深度准确性
上面是“DreamID-Omni虚拟数字人模型,清华 × 字节跳动统一可控以人为中心音视频生成框架”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_31436.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 觉晓法考最新版APP
觉晓法考最新版APP profile picture Maker
profile picture Maker ScienceDirect官网:一个拥有超过2650种期刊和45000余种图书的平台
ScienceDirect官网:一个拥有超过2650种期刊和45000余种图书的平台 AI设计神器官网使用入口,一款基于人工智能技术的在线设计平台
AI设计神器官网使用入口,一款基于人工智能技术的在线设计平台 推荐9款支持 Vue3 免费开源的前端 UI 组件库
推荐9款支持 Vue3 免费开源的前端 UI 组件库 老百晓在线小学语文网网页版官网入口
老百晓在线小学语文网网页版官网入口