
SuperCLUE是聚焦中文大模型的全维度综合性评测基准,专为精准评估中文大模型多维度性能表现打造。其以四大能力象限、12项基础能力为核心评测框架,融合多轮对话、客观题测试、主观题评估等多元评测方式,从语言理解与生成、知识应用、专业技能、环境适应与安全性四大维度展开全面评测;支持不同模型间横向对比,更可实现模型表现与人类表现的对标分析,为中文大模型的研发、优化与落地提供科学且专业的决策依据。此外,SuperCLUE新增AI Agent智能体专项评估,重点测试工具使用与任务规划核心能力,同时坚持定期更新评测榜单、发布详尽技术报告,持续推动中文大模型技术的迭代与发展。
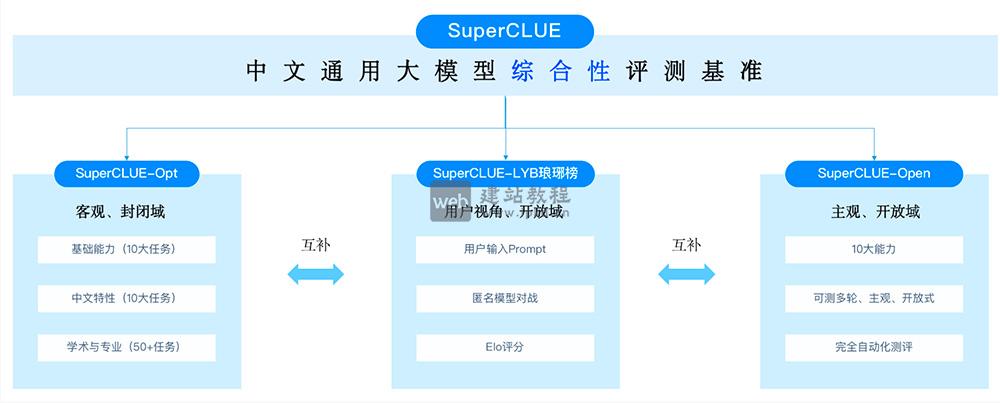
SuperCLUE核心功能:
1、全维度多能力评估:
覆盖语言理解与生成、知识应用、逻辑推理、代码能力、安全性等核心维度,全方位拆解中文大模型的综合性能。
2、多轮对话专项测试:
针对性评估模型在多轮对话场景中的上下文理解能力与回应连贯性,贴合实际交互应用需求。
3、主客观评测结合:
通过客观题实现模型基础能力的量化评分,借助主观题评估模型的内容创造性与场景适应性,评测结果更全面。
4、月度榜单动态更新:
每月迭代评测结果并发布最新榜单,清晰展示各模型性能变化,同步呈现模型与人类表现的对标数据。
5、专业技术报告输出:
发布详尽的评测技术报告,深度分析各模型的性能优势与能力短板,为研发者提供具体的优化参考方向。
6、AI Agent智能体评估:
新增智能体专项评测模块,重点考核模型的工具调用、任务规划与自主完成任务的核心能力,适配大模型智能体发展趋势。
SuperCLUE核心评测能力体系:
1、语言理解与生成:
涵盖语言理解与抽取、多轮对话、生成与创作三大能力,评测模型对文本的解析、上下文衔接能力,及创造性生成各类文本内容的能力。
2、知识理解与应用:
包含知识与百科、逻辑与推理、计算能力,考察模型的跨领域知识储备、逻辑推导能力,及基础与复杂数学运算的解题能力。
3、专业能力:
核心评测代码能力与AI Agent智能体能力,测试模型的代码理解、生成与问题解决能力,及智能体的工具使用、任务规划能力。
4、环境适应与安全性:
涉及角色扮演与安全性两大能力,评估模型在特定场景的角色适配能力,及内容生成的合规性、敏感信息识别与隐私保护能力。
5、中文特性专属能力:
作为中文大模型评测特色维度,覆盖字形拼音、字义理解、句法分析、文学诗词、成语歇后语、方言俗语、古文理解七大能力,精准考核模型对中文语言体系的适配与掌握能力。
SuperCLUE使用步骤:
1、了解评测体系:
访问SuperCLUE官方网站或GitHub项目页面,研读技术报告与评测文档,全面熟悉评测维度、方法与标准。
2、模型适配准备:
确保待评测的中文大模型可通过API或指定方式,与SuperCLUE评测系统实现稳定交互。
3、提交评测申请:
通过CLUEbenchmark官方邮箱联系评测组织者,按要求提交模型相关信息,等待评测任务安排。
4、参与正式评测:
配合组织者完成评测系统对接,由平台运行标准化测试流程,完成全维度能力评测。
5、查看评测结果:
在SuperCLUE官方榜单查看模型的详细评测结果,结合发布的技术报告,深度分析模型的性能表现与能力短板。
SuperCLUE多领域应用场景:
1、大模型研发与性能优化:
为模型研发人员提供标准化的全维度评测基准,精准定位模型在各能力维度的优势与不足,为模型架构调整、训练方法优化、数据集迭代提供科学的数据支撑。
2、学术研究与交流:
搭建统一的中文大模型评测框架,实现不同研究机构、研发团队的模型在同一标准下的横向对比,促进学术交流与研究成果共享,推动中文大模型领域的技术进步。
3、行业大模型选型与落地:
企业与行业开发者可依托评测结果,快速筛选适配智能客服、内容创作、智能办公等特定业务场景的中文大模型,提升行业应用开发的效率与可靠性。
4、安全与合规性检测:
借助平台的安全性专项评测能力,检测中文大模型内容生成的合规性、风险识别能力,保障AI产品的落地应用符合隐私保护、内容安全等相关政策要求,提升社会信任度。
5、中文NLP技术研究:
为中文自然语言处理领域的研究提供标准化评测工具,助力研究人员探索中文语言特性与大模型的适配规律,推动中文NLP技术的深度发展。
Github项目地址:https://github.com/CLUEbenchmark/SuperCLUE
PubMedQA:一个面向生物医学研究问题回答的专业数据集工具
H2O EvalGPT:H2O.ai推出的开源LLM大模型评估工具
LLMEval3:复旦大学NLP实验室推出的第三代中文大模型专业知识评测基准
LMArena:加州大学伯克利分校推出基于用户投票的AI模型评估平台
上面是“SuperCLUE官网:一个中文大模型的全维度综合性评测基准”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_28218.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 推荐一款免费好看的中文设计字体——字体传奇特战体
推荐一款免费好看的中文设计字体——字体传奇特战体 帝国cms方法之网站备份
帝国cms方法之网站备份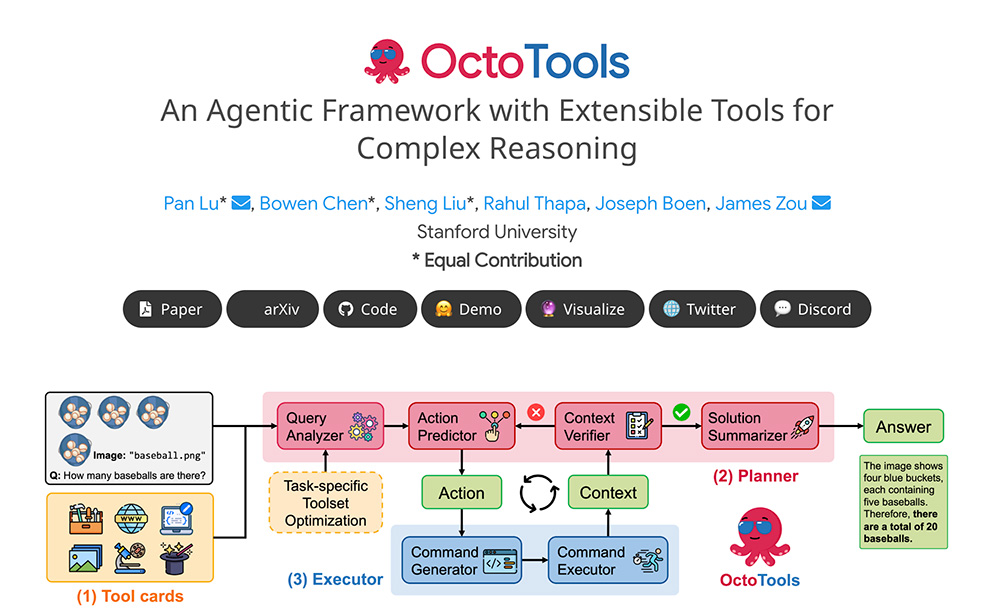 OctoTools:斯坦福大学研发的无需训练的高效工具框架,助力复杂任务推理与执行
OctoTools:斯坦福大学研发的无需训练的高效工具框架,助力复杂任务推理与执行