
CL-bench是腾讯混元与复旦大学联合推出的Context学习能力评测基准,专注衡量大语言模型从全新上下文信息中实时学习、应用知识的核心能力。该基准包含500个专家精心构建的复杂场景、1899个任务,全面覆盖领域知识推理、规则系统应用、程序性任务执行和经验发现与模拟四大类别。测试数据显示,当前最强模型GPT-5.1的任务解决率仅为23.7%,清晰揭示了当前AI“不会现场学习”的核心瓶颈,为后续模型优化提供了明确的新方向。

CL-bench的主要功能:
1、实时学习能力评测:
精准评测大语言模型从全新上下文信息中实时学习、灵活应用知识的能力,直击模型“现场学习”核心痛点。
2、大规模测试集构建:
构建包含500个复杂场景、1899个任务及31607个验证标准的大规模测试集,全面覆盖四类真实世界场景,贴合实际应用需求。
3、无污染数据设计:
采用全程无污染设计保障数据新颖性,通过虚构创作、现有内容修改、整合小众新兴内容三种方式,杜绝模型依靠记忆而非学习解决任务,确保评测结果真实可信。
4、序列依赖验证:
重点验证模型在序列依赖任务中的多轮推理能力,其中51.1%的任务需基于前期交互结果开展后续推理,贴合真实应用中的复杂场景。
5、多维度评估体系:
搭建全面的多维度评估体系,平均每个任务包含16.6个评估标准,从多个角度全方位检验模型对Context的理解与应用准确性,避免单一评估偏差。
CL-bench的技术原理:
1、自包含Context环境:
核心技术在于构建完全自包含的Context环境,确保解决任务所需的全部信息均显式提供于Context内部,无需外部检索、不允许隐藏假设。通过这种设计,强制模型必须从当前输入的新信息中汲取知识,而非调用预训练阶段封存的内部记忆,真实反映模型的Context学习能力,而非单纯的参数记忆能力。
2、三重无污染策略:
为实现精准无污染评估,采用三重核心技术策略:
一是专家完全虚构创作内容,如为虚构国家设计完整法律体系、创建具有独特语法的新编程语言;二是对现实世界内容进行系统性修改生成变体,包括调整历史事件、修改科学定义、优化技术文档等;三是纳入预训练数据集中代表性极低的小众或近期新兴内容,如前沿研究发现、新发布产品手册等,彻底规避模型记忆作弊。
3、复杂性与可验证性设计:
任务设计突出高复杂性与序列依赖性,51.1%的任务设置多轮交互机制,后续任务解决方案需依赖前期交互结果,既提升了任务难度,也精准模拟了真实工作场景。同时,每个任务均配备完全可验证的评估标准,平均每个Context关联63.2个验证标准,通过多角度、全方位评估,确保对模型性能的全面检验,杜绝单一指标带来的评估偏差。
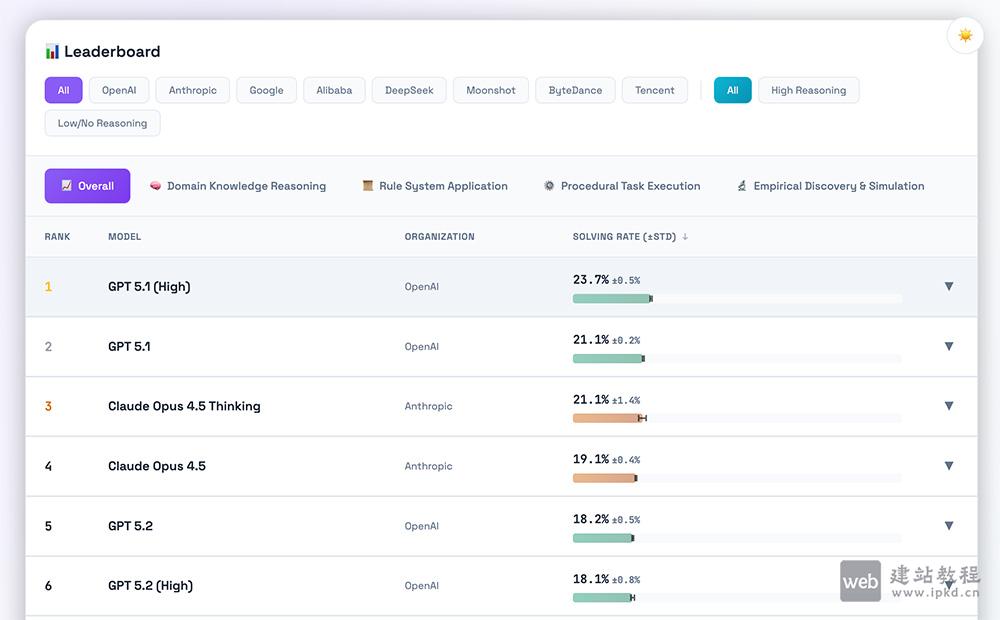
CL-bench的应用场景:
1、AI模型能力评估:
为研究机构和企业提供标准化的Context学习能力评测工具,精准定位模型在真实场景应用中的能力短板,明确模型优化的核心方向,提升优化效率。
2、新模型研发验证:
作为大语言模型研发过程中的核心测试环节,有效验证新版本模型是否真正实现从动态信息中学习的突破,而非单纯提升参数记忆能力,助力研发高质量模型。
3、行业解决方案选型:
帮助企业用户客观评估不同商用模型在特定业务场景下的Context学习表现,为企业选择适配自身需求的AI解决方案提供真实、客观的决策依据,降低选型成本。
4、教育培训领域:
可作为AI相关专业的教学案例和实验平台,帮助AI从业者清晰理解Context学习与参数学习的本质区别,培养其针对真实应用场景的模型设计、调优能力。
5、学术研究基准:
为学术界提供统一的Context学习研究基准,推动相关领域形成可对比、可复现的研究成果,加速Context学习理论与技术的整体进步,助力AI领域创新发展。
DataChef模型 - 上海AI Lab联合复旦大学开源的AI数据配方生成模型
Ardot官网使用入口,腾讯推出的支持文生UI、图转设计等功能
HY Motion模型使用入口,腾讯推出的开源文本到3D动作AI模型
HY-WU模型使用入口,腾讯混元推出的新一代功能性神经记忆框架
MagicAgent模型使用入口,荣耀 × 复旦大学AI智能体基础模型
标签: 复旦大学, 大模型评测基准, 机器学习模型, 腾讯AI, 腾讯混元AI
上面是“CL-bench:腾讯混元与复旦大学联合推出的Context学习能力评测基准”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://m.ipkd.cn/webs_30174.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!

 如何在Git中设置分支保护?
如何在Git中设置分支保护? Presenton:本地开源的AI PPT生成器,隐私安全与高效创作兼得
Presenton:本地开源的AI PPT生成器,隐私安全与高效创作兼得 医学题库:一个专为医学生、医生设计的在线学习和考试准备工具
医学题库:一个专为医学生、医生设计的在线学习和考试准备工具 WebWeaver:阿里通义双智能体研究框架,重塑开放性深度研究新范式
WebWeaver:阿里通义双智能体研究框架,重塑开放性深度研究新范式 Replit APP最新版
Replit APP最新版